Elasticsearch is a search engine based on the Lucene library. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents. Elasticsearch is developed in Java and is dual-licensed under the source-available Server Side Public License and the Elastic license, while other parts fall under the proprietary (source-available) Elastic License. Official clients are available in Java, .NET (C#), PHP, Python, Apache Groovy, Ruby and many other languages. According to the DB-Engines ranking, Elasticsearch is the most popular enterprise search engine. Source: Wikipedia

Even with databases spanning hundreds of millions of rows, Elasticsearch was able to deliver millisecond response times that were far superior to anything their Oracle systems could ever hope to deliver.
Regardless amount of data stored, elasticsearch is able to deliver results within miliseconds! But how, let’s breakdown internal working of elasticsearch.
Inverted Indexes
Under the hood elasticsearch keep data stored in a datastructure called ‘Inverted Indexes’ with a given mapping. Working of this datastructure is fairly easy to understand, we just use terms from database, let’s say admin, contact, california, etc as a key and store their frequency, occurence on primary db etc as values, so unlike having (index -> data), it’s stored as (data -> index), hence inverted. So, it’s able to achieve fast search responses because instead of searching the text directly, it searches an index.
Read more about this here.
APIs
Elasticsearch uses HTTP web interface, which means any interaction with elasticsearch uses the REST APIs exposed by elasticsearch itself. For example, here is the sample API for creating indexes with settings like shards and replicas(We will cover these futher in this read).
PUT /test_index?pretty
{
"settings" : {
"number_of_shards" : 2,
"number_of_replicas" : 1
},
"mappings" : {
"properties" : {
"tags" : { "type" : "keyword" },
"updated_at" : { "type" : "date" }
}
}
}
Scale it up.
Elasticsearch really works well for massive datastores. As we know now elasticsearch uses inverted indexes, we store inverted index broken down in multiple places that what we call shards, For availibilty these shards can be replicated according to requirement. So if demand arises, then it can scale horizontally really well.
Furthermore, these shards are stored in nodes, A node is a running instance of elasticsearch. Then we have clusters, an Elasticsearch cluster is a group of nodes that have the same cluster.name attribute. As nodes join or leave a cluster, the cluster automatically reorganizes itself to evenly distribute the data across the available nodes. If you are running a single instance of Elasticsearch, you have a cluster of one node.

Regular Database vs ElasticSearch
ElasticSearch is a great way of quick data retrieval but there is a trade-off, it requires additional disk space to store it’s own file system of inverted indexes. So, if you observe that you are experiencing delays because of there is tons of data which usually takes longer to search from, then probably you can opt for elastic search. Or you want to use features of ElasticSearch (eg: Stemming, Boosting, etc.) that might not be provided in your Regular Database.
Benchmarking along with Postgres
We’ve conducted an small head to head benchmarking test between ElasticSearch and Postgres in Ruby. Here, we ran it on Postgres using ActiveRecord ORM and used searchkick gem for ElasticSearch. Next we iteratively benchmarked queries in both cases and created 200k fake data in each iteration, query contains string match and date-time comparisions.
Queries:
# Postgres
Contact.where("(gaming_platform LIKE ? OR gaming_platform LIKE ?) AND education = ? AND last_used >= ? AND app_version <= ?", "%Wii%", "%Xbox%", "Bachelor", DateTime.parse("20220202T060000"), "0.8").limit(10000).order([:name_first, :name_last])# ElasticSearch (searchkick gem)
Contact.search("Wii Xbox", operator: "or", fields: [:gaming_platform], where: { education: 'Bachelor', last_used: {gte: DateTime.parse("20220202T060000")}, app_version: {lte: "0.8"}}, order: { name_first: :asc, name_last: :asc})
Results:
user system total real
SQL Queries On Postgres 0.060805 0.018111 0.078916 ( 0.085860)
Elasticsearch queries 0.005498 0.000000 0.005498 ( 0.010541)
↳ For 200000 records, found 94 records
user system total real
SQL Queries On Postgres 0.082427 0.000000 0.082427 ( 0.085349)
Elasticsearch queries 0.005763 0.000000 0.005763 ( 0.008134)
↳ For 400000 records, found 183 records
user system total real
SQL Queries On Postgres 0.088674 0.007989 0.096663 ( 0.101067)
Elasticsearch queries 0.004568 0.000761 0.005329 ( 0.005955)
↳ For 600000 records, found 274 records
user system total real
SQL Queries On Postgres 0.086693 0.015756 0.102449 ( 0.144879)
Elasticsearch queries 0.004756 0.001463 0.006219 ( 0.008626)
↳ For 800000 records, found 358 records
user system total real
SQL Queries On Postgres 0.105945 0.013521 0.119466 ( 0.204582)
Elasticsearch queries 0.005394 0.001918 0.007312 ( 0.105512)
↳ For 1000000 records, found 443 records
user system total real
SQL Queries On Postgres 0.139786 0.038830 0.178616 ( 0.325225)
Elasticsearch queries 0.004267 0.003694 0.007961 ( 0.138759)
↳ For 1200000 records, found 529 records
when plotted:
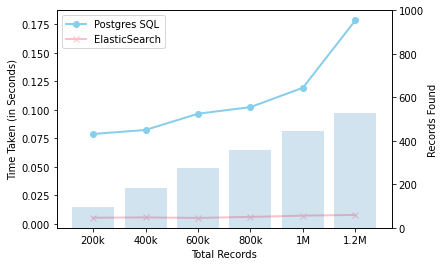
You can observe here that ElasticSearch is taking almost same time even with more and more data.
Conclusion
Elasticsearch is both a simple and complex product. We’ve so far learned the basics of what it is, how to look inside of it, and how to work with it using some of the REST APIs. Hopefully this tutorial has given you a better understanding of what Elasticsearch is and more importantly, inspired you to further experiment with the rest of its great features!



